差值的本意是两数相减后剩余的数值。略有不同地,这里的差值定义为「度量差异的值」。
I. 如何描述「差异」?
极差
级差指两极之差,即最大值和最小值相减后的值。值越小可以说明样本所有数据间的差异越小(紧密)。但是「值越大,所有数据之间的差异越大」,就有可能说不通了,比如下面这个例子。由于极差仅仅保留了样本最值之间的差异,因此只能粗略地描述数据的变化范围。

四分位差
四分位差保留了上四分位(Q3,百分比排列 75% 位置上的数)与下四分位(Q1,百分比排列 25% 位置上的数)之间的差异,也称作四分位距(IQR)。IQR 计算的是极差最中间的部分,因此可以用来描述中间 50% 数据的差异程度——数值越大中间的数据越分散,越小则越紧密也越靠近中位数。相比极差而言,IQR 不容易受到极端值的影响。
离差
如果说极差总倾向掩盖数值间的真实差异,那么离差(deviation)便毫无保留地呈现了每个数值的差异。离差是观测值距离特定参照的差值,因而一定程度上反映了实际情况与我们预期之间的差异。这里的特定参照可以是任何有意义的数值,比如预测值、均值、最值等。
方差、标准差
既然离差反映了各个数据与参照之间的差异,那么它的平均值就可用来反映所有数据与参照之间的平均差异。由于离差可能出现负值,比如选定平均数作为参照时计算的「离均差」,加总离差值就容易出现中和。为了避免这样的情况,很自然会想到对离差取绝对值或求平方和的做法。方差(Variance)便是这样一种方式计算而来的平均值。因为离差不尽相同,故将每个离差的平方求和再取平均,「尽最大努力保证公平」地代表数据间的差异。
有时候方差数值非常大,为了方便衡量常常会开根号,这时称为标准差(Standard Deviation)。
以上类型的差值足以描述一组数据的组内差异,那对于两组数据,是否也有类似的数字呢?
平均绝对误差、均方误差、均方根误差
方差的计算启发我们,在离差不尽相同且可能存在负值的时候,可以采用「化负为正」和「平均化」的思想计算出当前数据的差异。在机器学习中经常要计算预测值和真实值之间的差异,这样的差异称为误差(Error)。误差是模型评估和优化的依据。下面简单列举回归问题中常见的几种误差:
平均绝对误差(MAE)利用绝对值将误差「化负为正」,最后求和取平均。
均方误差(MSE)利用平方将误差「化负为正」,最后求和取平均,相较于 MAE 要平滑。
均方根误差(RMSE)是 MSE 的开方值,实际含义与 MSE 一致。
协方差、相关系数
协方差(Covariance)数值上等于两组数据的离均差乘积的平均值。与方差不同的是,协方差考虑了两组数据的离均差,因此能够描述两组数据间的某种差异——当数值越小时,说明两组数据所呈现的变化趋势的差异就越明显。
同样为了方便衡量,将协方差与标准差乘积的比值构成相关系数(Correlation Coefficient)。
决定系数
决定系数(Coefficient of Determination)能够描述两组数据的相似程度,它的值根据公式1-MSE/方差计算而来。两组数据越接近,MSE就越低,由于方差固定,决定系数就会接近于 1(完全相同)。
如果数据呈现的是一种线性变化时,决定系数恰好等于相关系数的平方值,别名 R 方(R-square)可能就是这样来的。
II. 如何计算「差异」?
从上面可以看出,离差的计算可能是最核心的——方差、协方差、MAE、MSE都依赖于它;把观测值固定为最大值和 Q1,参照值设为最小值和 Q3 就可以计算极差和 IQR。下面我们且看如何用 Python 实现所有类型的差值:
温馨提示:以下内容涉及中文编程的理念,可能引起极度不适。
离差
1 | def 离差(观测值, 参照值): |
1 | # 下面的X均为向量 |
极差
1 | def 极差(X): |
四分位差
1 | def 四分位差(X): |
方差、标准差
你可能需要了解什么是自由度(Degrees of Freedom)。
1 | def 方差(X, 自由度=None): |
平均绝对误差、均方误差、均方根误差
1 | def MAE(X, Y, 自由度=None): |
协方差、相关系数、决定系数
1 | def 协方差(X, Y, 自由度=None): |
抽象总结一下
假设离差是一类复合函数F(f),其中f = □ - ■。
| 差值类型 | 函数 F | 变量 □ | 变量 ■ | |||
|---|---|---|---|---|---|---|
| 1 | 离差 | □ - ■ | ||||
| 2 | 离均差 | □ - ■ | 平均值 | |||
| 3 | 极差 | F1 | 最大值 | 最小值 | ||
| 4 | 四分位差 | F1 | Q3 | Q1 | ||
| 5 | MAE | ∑ \ | F1\ | / 自由度 | ||
| 6 | MSE | ∑ (F1)^2 / 自由度 | ||||
| 7 | RMSE | √ F6 | ||||
| 8 | 方差 | ∑ (F1)^2 / 自由度 | ||||
| 9 | 标准差 | √ F8 | ||||
| 10 | 协方差 | ∑ F2*F2 / 自由度 | ||||
| 11 | 相关系数 | F10 / F9*F9 | ||||
| 12 | 决定系数 | 1 - F6 / F8 |
III. 如何利用「差异」?
识别异常值
分位数和 IQR 的概念让我们学会怎么画箱线图(Boxplot),同时也教会我们怎样识别异常数据。箱线图有箱有线——箱的边界是上、下四分位数,长度则由 IQR 决定;箱里的中线表示中位数,箱外的上线和下线各距离箱的边界 1.5 倍 IQR,两线以外标记异常数据。
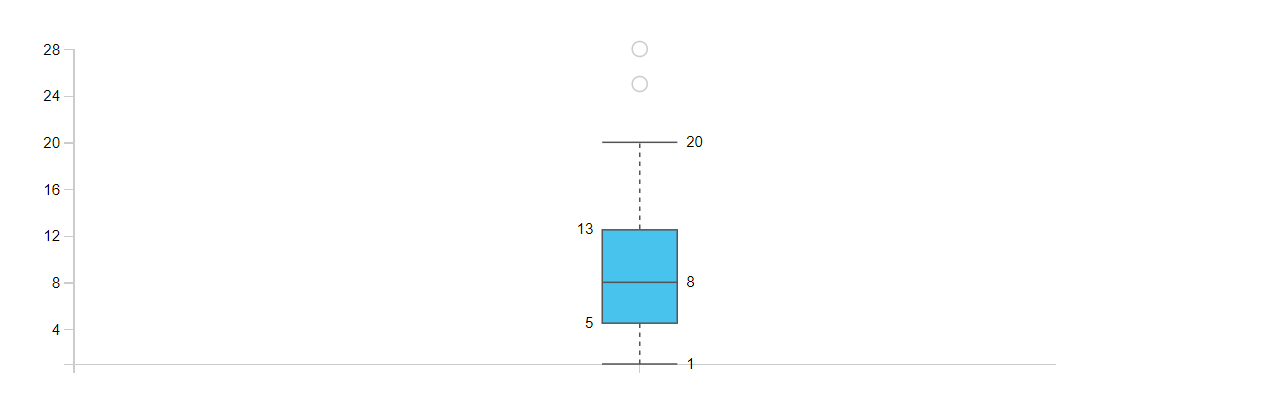
我们把上面的 IQR 倍率设为可调整参数,可以这样实现异常数据的识别:
1 | def 识别异常数据(X, IQR倍率=1.5): |
如果只是想知道每一行数据是否存在异常,停止第5行的索引(即只保留X[·]中的代码)即可。
标准化
数据的标准化(Standardization)很常见于指标的计算中,例如相关系数就可看作是经过标准化的协方差。有时也称作缩放(Scaling)或归一化(Normalization),目的是将数据从原始空间转换到新的有限空间内。归一化特指将数据缩放到[0, 1]的范围,此时归一化后的数值的和为 1。标准化可以消除量纲差异,便于不同数据之间的比较和运算,有时也能加快模型的收敛。
常见的标准化方法有 Min-max 缩放、平均归一化、z分数标准化等等,这些都用到了离差的计算。例如,
1 | def min_max缩放(X): |
特征选择
差值还可以用来选择预测能力较强的特征(变量)。应该如何量化预测能力呢?简而有效的做法是,假设某个特征与目标变量越相关,那么它的预测能力越强。这样一来就可以根据相关系数的大小来筛选特征,比如剔除相关性较弱的特征。
1 | def 剔除相关性较弱特征(X, y, 阈值=0.2): |
模型评估和优化
损失函数在模型评估和优化中的地位非常重要。从某个角度看,机器学习就像是不断求解损失函数最优化的过程。MAE、MSE、RMSE 都可以作为回归模型的损失函数,例如线性回归的最小二乘法和逻辑回归的 L2 正则项。
1 | from sklearn.linear_model import LogisticRegression |
模型选择
在《机器学习》书中,周志华老师认为误差的期望值 ≈ 预测值相对真实值的偏差 + 模型预测值的方差 + 样本噪声的方差。「偏差度量了模型的预测与真实结果的偏离程度,刻画的是算法本身的拟合能力;方差度量了同样大小训练集的变动所导致的算法能力的变化,刻画的是数据扰动所造成的影响;噪声表达了任何算法所能达到的期望误差的下界。」
随着训练进程不断推移,模型的拟合能力逐渐变强,偏差也在逐渐缩小,然而方差却增大了。按照偏差-方差权衡准则(Bias-variance Tradeoff),因为实际上很难获得偏差和方差都很小的模型,我们因此可以选择偏差和方差适中的模型。
| 训练过程 | 模型复杂度 | 偏差 | 方差 | 效果 |
|---|---|---|---|---|
| T1 | 低 | 高 | 低 | 欠拟合 |
| T2 | 中 | 中 | 中 | 刚刚好 |
| T3 | 高 | 低 | 高 | 过拟合 |
IV. 进一步阅读
- 从协方差到相关系数 - 陆尤
- Highlighting Outliers in your Data with the Tukey Method - Bacon Bits
- 机器学习中偏差、误差和方差的区别和联系 - J JR
- 损失函数为平方形式的数学解释 - 忆臻
- 什么是偏差-方差权衡 - 毕加索·陈